America’s healthcare system has become far too complex and costly to continue business as usual.
In 2012, the Institute of Medicine (IOM) basically said that healthcare in America was a mess:
“America's health care system has become far too complex and costly to continue business as usual. Pervasive inefficiencies, an inability to manage a rapidly deepening clinical knowledge base, and a reward system poorly focused on key patient needs, all hinder improvements in the safety and quality of care and threaten the nation's economic stability and global competitiveness. Achieving higher quality care at lower cost will require fundamental commitments to the incentives, culture, and leadership that foster continuous ‘learning’, as the lessons from research and each care experience are systematically captured, assessed, and translated into reliable care.”
To address these dark realities, the IOM called for a “Learning Health Care System”, and convened the Committee on the Learning Health Care System in America. The committee’s initial report, Best Care at Lower Cost: The Path to Continuously Learning Health Care in America, identified that,
“…emerging tools like computing power, connectivity, team-based care, and systems engineering techniques—tools that were previously unavailable—make the envisioned transition possible, and are already being put to successful use in pioneering health care organizations. Applying these new strategies can support the transition to a continuously learning health system, one that aligns science and informatics, patient-clinician partnerships, incentives, and a culture of continuous improvement to produce the best care at lower cost.”
Enter Big Data.
Healthcare is at a tipping point where Big Data is concerned—fueled by a decade of digital medical records; the aggregation of years of research and development into electronic databases; and new transparencies and access by both the federal government and public sectors.
Mobile technologies, sensors, genome sequencing and analytic software advances are all working together to push healthcare into the Big Data age. When we hear stories of interoperability nightmares, vendor squabbles, and providers being hung out to dry, it can seem that there is little coordinated effort toward achieving what we need. Now that Big Data is upon us, the quagmire seems bound to thicken.
Coordinated Efforts
Imagine my delight—when knee-deep in project research—I stumbled upon the complementary efforts of several large U.S. government entities focusing on the optimization of Big Data use in healthcare. Maybe it’s just me, but I was tickled pink to discover a pattern of alignment creating a firm foundation for healthcare’s Big Data push—and just had to share. If it’s not news to you, bear with me. But if it is—prop up your feet and enjoy a quick primer about the framework being created to make the most of healthcare’s Big Data bonanza.
We’ve established that the IOM set the stage by calling out the healthcare mess, and establishing the need for a Learning Health Care System. Enter the National Institutes of Health (NIH)—one of America’s key players in healthcare’s Big Data game. As a result of recommendations from its Data and Informatics Working Group (DIWG) in June 2012, it created the Big Data to Knowledge (BD2K) initiative in an effort to capitalize on the massively growing body of biomedical data. The mission of BD2K is four-fold:
1. Improve the ability to locate, access, share and use biomedical Big Data.
2. Develop and disseminate data analysis methods and software.
3. Enhance training in biomedical Big Data and data science.
4. Establish centers of excellence in data science.
Certainly, a major factor influencing the massive amount of biomedical data available today is the widespread adoption of EHRs in health systems across the world. This is creating an accumulation of valuable data like nothing ever imagined—providing an opportunity for clinical and translational research, the ability to survey public health in nearly real time and improve the foundational quality of care.
However, though EHR adoption and the achievement of meaningful use are key to this process, they’re only the starting point for such an evolution—especially as we need to access data from a variety of sources.
In order to effectively deal with such a large volume of data in various locations, some experts recommend the use of a “federated” approach to a national learning system. This means that data remains in place until it’s requested by other members of the learning system through a query process of other members who then provide the needed data—based on the format of the query. To illustrate, a conceptual model for data query making use of Federated Data Networks (FDNs) looks something like this:
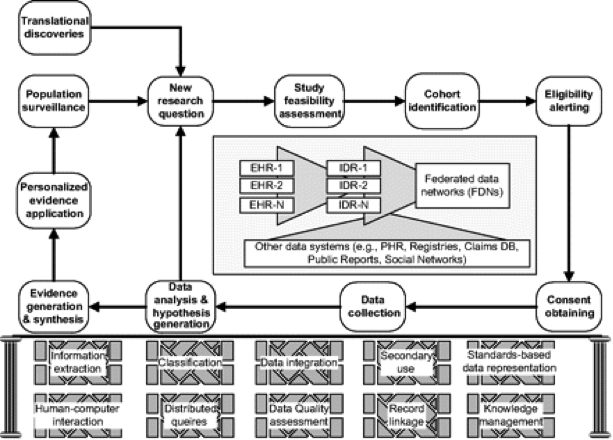
“A conceptual model for clinical research informatics consisting of an informatics-enabled clinical research workflow, heterogeneous data sources, and a collection of informatics methods and platforms. EHR, electronic health records; IDR, integrated data repositories; PHR, personal health records.” Copyright © by the American Medical Informatics Association. “Clinical Research Informatics: A Conceptual Perspective” by M. Kahn and C. Weng is licensed under CC by 2.0.
A foundational need for the use of a federated system is a standardized query structure—which is why the Office of the National Coordinator for Health Information Technology (ONC) introduced the Query Health initiative in 2011:
“a collaboration to develop a national architecture for distributed, population-level health queries across diverse clinical systems with disparate data models.”
The query model supports a federated approach to a rapid learning system as described by the ONC:
“In recent years, the use of distributed queries has become a growing focus of health information technology. Instead of relying on centralized databases, the distributed query approach provides access to aggregate data for specific analytical purposes without identifying individual information, and allows the data to remain behind the health care organization’s firewalls, thus maintaining patient privacy and security. By ‘bringing the question to the data,’ health care providers in their local communities are empowered to respond proactively to disease outbreaks, understand the efficacy of drug treatments, and monitor health trends. This ability to understand large-scale health trends can contribute to reducing the cost of health care and most importantly, improving the health of our citizens.”
In order for a query structure to be effective, standards and services for distributed population queries must be in place—which helps to enhance transactional speed while lowering the costs of data transfer. To achieve this, Query Health uses a variety of standards—including a Query Envelope, a Data Model, Health Quality Measures Format (HQMF) and Quality Reporting Document Architecture (QRDA), some of which are already built into Meaningful Use requirements.
The overall design of Query Health is depicted below—in which stakeholders are able to develop queries which are securely distributed to data partners, who process them and return aggregate counts. This process prevents the release of sensitive data from individual sites.
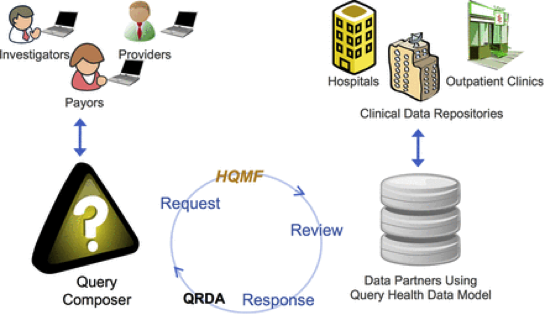
Copyright © by the American Medical Informatics Association. “Query Health: standards-based, cross-platform population health surveillance” by J. Klann et al. is licensed under CC by 3.0.
Individual technologies that are being used in Query Health are familiar architectures that are used in many large initiatives: an NIH-funded framework—Informatics for Integrating Biology and the Bedside (i2b2) is used as a composer, PopMedNet is used for distribution and authentication, i2b2 and hQuery are used for back-end data warehousing to connect to Query Health, and Health Quality Measures Format (HQMF) is used for standardized query format communications.

Copyright © by the American Medical Informatics Association. “Query Health: standards-based, cross-platform population health surveillance” by J. Klann et al. is licensed under CC by 3.0.
The Query Health initiative has been very successful in creating a standards-based approach for distributed population health queries that is vendor-neutral, and demonstrates enthusiasm for collaborative Learning Health System (LHS) efforts among a variety of stakeholders.
A key outcome of the initiative was the glaring lack of common data models among clinical systems. This has resulted in the launch of an additional initiative by the ONC, the Data Access Framework (DAF), which seeks to provide
“standards and implementation guidance for cross-platform normalized data access. DAF is a multilevel initiative that will encompass standards for both intra- and inter-organizational queries on both individuals and populations.”
DAF is one of the active initiatives within the ONC’s Standards and Interoperability (S&I) Framework, which
“is a collaborative community of participants from the public and private sectors who are focused on providing the tools, services and guidance to facilitate the functional exchange of health information.”
It’s all good news, and provides some needed reassurance that there may actually be a complementary approach to discovering solutions to meet the quagmire of needs in America’s healthcare system. If we’re ever going to optimize the potential for Big Data in healthcare, it will be essential that we do it together—in a collaborative and unified fashion that focuses on creating an effective, efficient and reliable approach that catalyzes Big Data progress from which the entire world can benefit.
Log in or register for FREE for full access to ALL site features
As a member of the nuviun community, you can benefit from:
- 24/7 unlimited access to the content library
- Full access to the company and people directories
- Unlimited discussion and commenting privileges
- Your own searchable professional profile






.jpg)
